It’s no secret that I’m into building toy compilers and programming languages. Today I’m introducing something that’s not a toy (I hope). Today, I’m introducing php-compiler (among many other projects). My hope is that these projects will grow from experimental status into fully production ready systems.
JIT? AOT? VM? What The Heck?
Since I’m going to be talking a lot about compilers and components in this post, I figure it’s good to start with a primer on how they work, and how the different types behave.
Types of Compilers
Let’s start by talking about the 3 main categories of how programs are executed. (There are definitely some blurred lines here, and you’ll hear people using these labels to refer to multiple different things, but for the purposes of this post):
Interpreted: The vast majority of dynamic languages use a Virtual Machine of some sort. PHP, Python (CPython), Ruby, and many others may be interpreted using a Virtual Machine.
A VM is - at its most abstract level - is a giant switch statement inside of a loop. The language parses and compiles the source code into a form of Intermediary Representation often called Opcodes or ByteCode.
The prime advantage of a VM is that it’s simpler to build for dynamic languages, and removes the “waiting for code to compile” step.
Compiled: The vast majority of what we think of as static languages are “Ahead Of Time” (AOT) Compiled directly to native machine code. C, Go, Rust, and many many others use an AOT compiler.
AOT basically means that the full compilation process happens as a whole, ahead of when you want to run the code. So you compile it, and then some time later you can execute it.
The prime advantage of AOT compilation is that it can generate very efficient code. The (prime) downside is that it can take a long time to compile code.
Just In Time (JIT): JIT is a relatively recently popularized method to get the best of both worlds (VM and AOT). Lua, Java, JavaScript, Python (via PyPy), HHVM, PHP 8, and many others use a JIT compiler.
A JIT is basically just a combination of a VM and an AOT compiler. Instead of compiling the full program at once, it instead runs the code on a Virtual Machine for a while. It does this for two reasons: to figure out which parts of the code are “hot” (and hence most useful to be in machine code), and to collect some runtime information about the code (what types are commonly used, etc). Then, it pauses execution for a moment to compile just that small bit of code to machine code before resuming execution. A JIT runtime will bounce back and forth between interpreted code and native compiled code.
The prime advantage of JIT compilation is that it balances the fast deployment cycle of a VM with the potential for AOT-like performance for some use-cases. But it is also insanely complicated since you’re building 2 full compilers, and an interface between them.
Another way of saying this, is that an Interpreter runs code, whereas an AOT compiler generates machine code which then the Computer runs. And a JIT compiler runs the code but every once in a while translates some of the running code into machine code, and then executes it.
Some more definitions
I just used the word “Compiler” a lot (along with a ton of other words), but each of these words have many different meanings, so it’s worth talking a bit about that:
Compiler: The meaning of “Compiler” changes depending on what you’re talking about:
When you’re talking about building language runtimes (aka: compilers), a Compiler is a program that translates code from one language into another with different semantics (there’s a conversion step, it isn’t just a representation). It could be from PHP to Opcode, it could be from C to an Intermediary Representation. It could be from Assembly to Machine Code, it could be from a regular expression to machine code. Yes, PHP 7.0 includes a compiler to compile from PHP source code to Opcodes.
When you’re talking about using language runtimes (aka: compilers), a Compiler is usually implied to be a specific set of programs that convert the original source code into machine code. It’s worth noting that a “Compiler” (like gcc for example) is normally made up of several smaller compilers that chain together to transform the source code.
Yes, it’s confusing…
Virtual Machine (VM): I mentioned above that a VM is a giant switch statement inside of a loop. To understand why it’s called a “Virtual” machine, let’s talk for a second about how a real physical CPU works.
A real machine executes instructions that are encoded as 0’s and 1’s. Those instructions can be represented as assembly code:
incq %rsi addq $2 %rsiThis basically adds 1 to the
rsiregister, then adds 2 to it.Compare this to the PHP opcodes for the “same” operations:
POST_INC !0 ASSIGN_ADD !0, 2Aside from naming conventions, they are basically conceptually the same. The PHP OpCodes are the building block instructions for the PHP VM, just like assembly is the building block instructions for a CPU.
The difference, is that assembly instructions are very low level and there are relatively few of them, where PHP’s VM OpCode instructions have more logic built in. An example of this is the
incqassembly instruction expects its argument to be an integer. PHP’sPOST_INCinstruction on the other hand contains all of the logic necessary to convert the argument to an integer first. There’s a LOT more logic in the PHP VM which is what makes PHP (and any interpreted language) possible, and which is why interpreted languages often use one.Parser: A parser is very similar to a compiler but it doesn’t translate the source code, it just changes the representation. This can be from text (the source code that you write) into an internal data structure (such as a tree or a graph).
Abstract Syntax Tree (AST): An AST is an internal data structure that represents the source code of a program as a tree. So instead of
$a = $b + $c;you get something likeAssign($a, Add($b, $c)). The key property that makes it a tree is that every node has exactly one parent. PHP internally parses from the source file into an AST before compiling to Opcodes.Given the following code:
$a = $b + $c; echo $a;We could expect an AST to look something like:
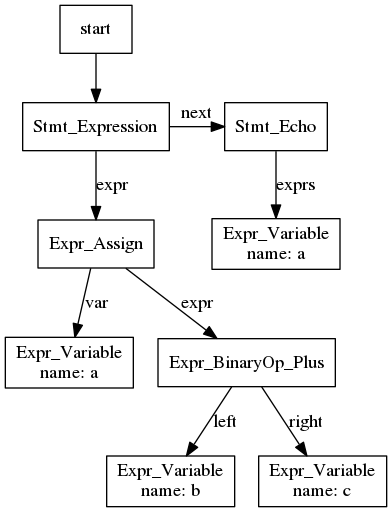
Control Flow Graph (CFG): A CFG looks a lot like an AST but instead of each node having one parent, they can have multiple. This is because a CFG includes edges for loops, etc such that you can see all the possible ways control can flow through code. PHP’s Opcache’s Optimizer uses a CFG internally.
Given the following PHP code:
function(int $a): int { $value = 1; if ($a > 0) { $value = $value + 1; } $result = $a + $value; return $result; }We could expect a CFG to look something like:
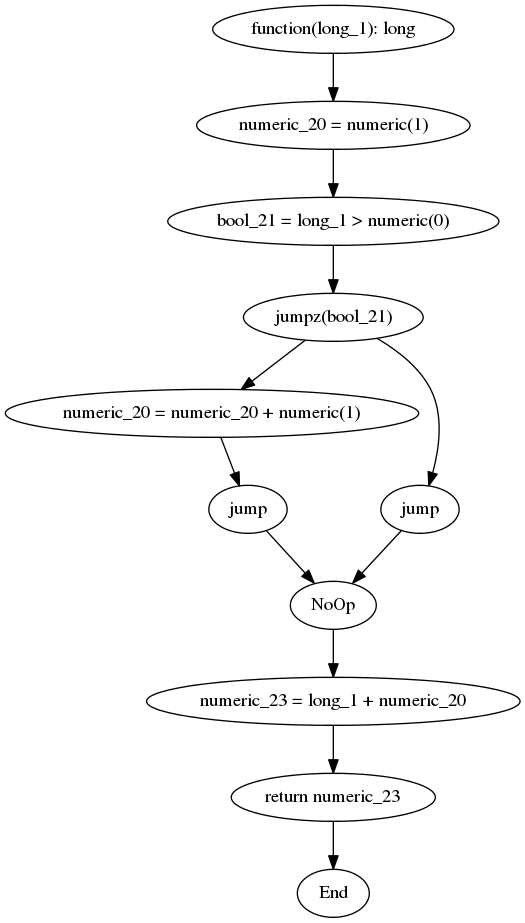
In this case,
longbasically means a PHP integer,numericmeans either an integer or float, andjumpzmeans goto a different instruction based on ifbool_21is0or not.Notice how we can see the different paths the code can take. This is the same reason a compiler internally uses a CFG. But instead of an image, it’s done using data structures.
Intermediary Representation (IR): An IR is basically a programming language that lives entirely within a compiler. You never write in an IR, instead letting it be generated for you. The reason for the IR though, is so that the compiler can manipulate it (for example, to implement optimizations) as well as keeping components of the compiler separate (and hence easier to maintain). The AST and CFG structures above are forms of IR.
A bit of (relevant) history
My first attempt at running PHP on top of PHP was with PHPPHP way back in 2013. The project attempted to “translate” php-src from C into PHP. It was never designed to run “fast” (fast in quotes, since it’s about 200x slower than PHP and had no real way of going faster). It was done for fun, and mainly as a joke/interesting teaching toy.
About a year and a half later I built Recki-CT. It used a different model. Rather than re-implementing PHP in PHP, I built a multi-stage compiler. It would parse PHP into an AST, convert the AST into a CFG, perform some optimizations, and then emit code using a backend. I built two primary backends for it, one to compile to a PECL extension, and one using JitFu to execute it directly, compiling just in time and executing as native machine code. This approach worked quite well, but wasn’t really practical for a few reasons.
A few years later, I picked the idea back up and instead of building a single monolithic project, decided to build out a series of related projects to parsing and analyzing PHP. PHP-CFG implemented the CFG parsing. PHP-Types implemented a type inference system. PHP-Optimizer implemented a basic set of optimizations on top of the CFG. These tools were designed to be incorporated into other projects for different usages. For example, Tuli was an early static analyzer for PHP code. And PHP-Compiler was a poor attempt at compiling the PHP into lower level code, and never really went anywhere.
The biggest challenge I faced to making a useful, low level compiler was the availability (or lack) of a suitable backend. libjit (which JitFu used) was good and fast, but it couldn’t generate binaries. I could have written a c extension binding to LLVM (which is what HHVM used, among many many others), but that’s a TON of work and I didn’t feel like going down those paths. So on the shelf the projects went.
Enter PHP 7.4 and FFI
No. PHP 7.4 is not out yet. It won’t be out for likely at least 6 months. But a few months ago, a little RFC was accepted to incorporate an FFI Extension into PHP. I decided to start playing around with it to see how it worked.
After a bit of playing, I remembered my old compiler projects. And I started wondering how hard it would be to pull libjit in to PHP. But then I remembered the fact it couldn’t generate executable files. And so I started searching to see what else was out there. I stumbled upon libgccjit. And then the rabbit hole went down and down and down.
Let’s take a look at all of the new projects I’ve been working on over the past few months:
FFIMe
My first step was to code generate a wrapper around libgccjit. FFI requires a C declaration file similar to a header file, but can’t handle C pre-processor macros. If that sentence doesn’t make sense, just know that every library comes with one or more “header” files which describe the functions, and FFI needs a cut-down version of that header file.
I didn’t feel like hand-editing a few hundred function declarations, and a bunch of type code. So I decided to build a library to do it for me.
Enter FFIMe.
The project started as a C pre-processor to “compile” header files into a form good enough for FFI. This got me started.
After a month or so of work, I realized I needed more. I couldn’t just pre-process the headers, I needed to actually parse them. So after some significant refactoring, FFIMe can now code-generate helpers for use with FFI. It’s by no means perfect and complete, but it is plenty good enough for my purposes so far.
$ffime = new FFIMe\FFIMe('/usr/lib/x86_64-linux-gnu/libgccjit.so.0');
$ffime->include('libgccjit.h');
$ffime->codegen('libgccjit\\libgccjit', __DIR__ . '/libgccjit.php');
Basically, it takes a path to a Shared Object File, and then one or more #include directives. It parses the resulting C, eliminates any code not really compatible with FFI, and then code generates a class (well, a lot of them). The generated file can now be committed (here’s the one from the above example).
If you take a peak at that file, you’ll see a BUNCH of code (nearly 5000 lines). Included are all numeric #defines from the C headers as class constants, all ENUMs as class constants, all functions, and wrapper classes around all of the underlying C types. It also includes all other headers recursively (hence why the above header has some seemingly unrelated file functions).
Usage is pretty straightforward (ignore what the library is doing, just focus on the types and the call, and compare to the equivalent C code):
$lib = new libgccjit\libgccjit;
// gcc_jit_context *context = gcc_jit_context_acquire();
$context = $lib->gcc_jit_context_acquire();
// gcc_jit_context_release(context);
$lib->gcc_jit_context_release($context);
Now, we can work with C libraries in PHP, just like they were C! Woot!
It’s worth noting, that while I did run into a few rough edges with FFI (which have all been since fixed), it’s fairly straight forward to work with. Definitely easier than some other dark corners of PHP (cough Streams cough). Dmitry did a nice job with it.
PHP-CParser
When I did the refactoring to FFIMe, I decided to build a full blown C parser. This is basically the same thing as Nikita’s PHPParser does but for C instead of PHP.
Not all C syntax is supported yet, but it does use a standard C grammar, so it’s theoretically able to parse everything.
It does this by first running a C pre-processor on the included files. This will resolve all normal directives like #include, #define and #ifdef, etc. From there, it parses the code into an AST (inspired by CLANG’s).
So, for example, the following C code:
#include "includes_and_typedefs.h"
#ifdef TEST_FLAG
typedef int A;
#else
typedef int B;
#endif
And includes_and_typedefs.h:
#define TEST_FLAG
typedef int TEST;
Will result in the following Abstract Syntax Tree:
TranslationUnitDecl
declarations: [
Decl_NamedDecl_TypeDecl_TypedefNameDecl_TypedefDecl
name: "TEST"
type: Type_BuiltinType
name: "int"
Decl_NamedDecl_TypeDecl_TypedefNameDecl_TypedefDecl
name: "A"
type: Type_BuiltinType
name: "int"
]
The blue names are the classnames of the objects, and the red lowercase ones are the names of the properties of said objects. So the outer object here is a PHPCParser\Node\TranslationUnitDecl object, which has an array property declarations. Etc…
It’s probably rare that people will need to parse C code in PHP, so I imagine the uses of this library are going to be pretty constrained to FFIMe. But if you have a use for it, run with it!
PHP-Compiler
I picked back up the PHP-Compiler project, and ran with it. This time, I was adding a few stages to the compiler. Rather than compiling directly from the CFG to native code, I decided to implement a Virtual Machine interpreter (which is basically how PHP works). This is the approach that I took with PHPPHP but WAY more mature. But instead of stopping there, I also built a compiler that can take the virtual machine opcodes and generate out native machine code. This enables true JIT (Just In Time) Compilation.
But beyond JIT, it also enables AOT (Ahead of Time) Compilation. So not only can I run or compile while running, but I can also give it a codebase and have it generate out a native machine code binary.
This means that I can (in theory right now) eventually compile the compiler itself to native code. Which has a shot at making the interpreter side reasonably fast (no idea if it will be anywhere close to PHP7’s speed, but I can hope). And as long as the compilation step can be reasonably quick, this has a shot at not only implementing PHP in PHP, but also being insanely fast while doing it.
I started building PHP-Compiler on top of libgccjit, and the initial results are more than promising. A simple set of benchmarks taken from PHP’s own benchmark suite show that while there’s a LOT of overhead right now, the compiled code can really shine.
The following benchmarks compare PHP-Compiler to PHP 7.4 with and without OpCache (Zend Optimizer), PHP 8’s experimental JIT (enabled and disabled).
| Test Name | 7.4 (s) | 7.4.NO.OPCACHE (s) | 8.JIT (s) | 8.NOJIT (s) | bin/jit.php (s) | bin/compile.php (s) | compiled time (s) |
|---|---|---|---|---|---|---|---|
| Ack(3,10) | 1.1752 | 1.9196 | 0.6796 | 1.1634 | 0.5025 | 0.2939 | 0.2127 |
| Ack(3,8) | 0.0973 | 0.1215 | 0.0534 | 0.0853 | 0.3053 | 0.2943 | 0.0148 |
| Ack(3,9) | 0.3018 | 0.3730 | 0.1776 | 0.3010 | 0.3458 | 0.2937 | 0.0540 |
| array_access | 2.5958 | 2.6941 | 1.6697 | 2.6075 | 0.5495 | 0.2936 | 0.2685 |
| fibo(30) | 0.0760 | 0.1035 | 0.0429 | 0.0743 | 0.3065 | 0.2946 | 0.0110 |
| mandelbrot | 0.0434 | 0.1090 | 0.0323 | 0.0440 | 0.3186 | 0.3075 | 0.0146 |
| simple | 0.0650 | 0.0866 | 0.0391 | 0.0673 | 0.3094 | 0.2988 | 0.0120 |
As you can see, the startup penalty is really heavy (it’s all in PHP remember). The compiled code though (both in the JIT and AOT modes) is significantly faster than 8 with JIT compilation for extremely heavy use-cases.
It’s worth noting, that this is absolutely not an apples-to-apples comparison, and I wouldn’t expect the same numbers in a production-ready system. But it does give an indication as to the promise of such an approach…
Currently, there are 4 commands that you can use:
php bin/vm.php- Run code in a VMphp bin/jit.php- Compile all code, and then run itphp bin/compile.php- Compile all code, and output a.ofile.php bin/print.php- Compile and output CFG and the generated OpCodes (useful for debugging)
And it runs just like PHP on the command line:
me@local:~$ php bin/jit.php -r 'echo "Hello World\n";'
Hello World
Yes, the echo "Hello World\n"; is running as native machine code there. Overkill? Definitely. Fun? Amazing!
You can see more here in the readme.
I paused building because of a question: is it worth continuing down with libgccjit, or would I be better off with LLVM?
Well, there’s only one way to find out…
PHP-Compiler-Toolkit
As you’ve likely seen, I’m not great at naming things…
PHP-Compiler-Toolkit is an abstraction layer on top of libjit, libgccjit, and llvm.
Basically you “build” C like code into a custom Intermediary Representation using a PHP native interface. For example (note, long long is a 64-bit integer, just like PHP’s int type):
long long add(long long a, long long b) {
return a + b;
}
Could be built as:
use PHPCompilerToolkit\Context;
use PHPCompilerToolkit\Builder\GlobalBuilder;
use PHPCompilerToolkit\IR\Parameter;
$context = new Context;
$builder = new GlobalBuilder($context);
// First, let's get a reference to the type we want to use:
$type = $builder->type()->long_long();
// Next, we need to create the function:
$func = $builder->createFunction(
'add', // The function's name
$type, // The return type of the function
false, // Is the function variadic?
new Parameter($type, 'a'), // Argument 0
new Parameter($type, 'b') // Argument 1
);
// We need a block in the function (blocks contain code)
$main = $func->createBlock('main');
// Now, we add the two arguments
$result = $main->add($func->arg(0), $func->arg(1));
// We want the block to return the result of addition of the two args:
$main->returnValue($result);
This “describes” the code. From there, we can pass the context into a Backend to compile:
use PHPCompilerToolkit\Backend;
$libjit = new Backend\LIBJIT;
$libgccjit = new Backend\LIBGCCJIT;
$llvm = new Backend\LLVM;
// Compile using libjit with full optimizations: -O3
$result = $libjit->compile($context, Backend::O3);
And then just grab a callable:
$cb = $result->getCallable('add');
var_dump($cb(1, 2)); // int(3)
And that’s pure native code.
This allows me to build the frontend (PHP-Compiler) against this abstraction, and then swap out backends for testing.
It turns out, it was a good idea to test, because the initial looks show how slow libgccjit is in this setup. Compilation times:
| Backend | Compile Time | RunTime (1,000,000 runs) |
|---|---|---|
| libjit | 0.000611066818237 | 0.12596678733826 |
| libgccjit | 0.026333808898926 | 0.12308621406555 |
| llvm | 0.000663995742797 | 0.12417387962341 |
So while they all are within a reasonable efficiency for runtime, the compilation time is off the charts for libgccjit. So this shows that there may be some truth to using LLVM instead…
Oh, and for such a simple function, the overhead of FFI is substantial. A PHP version of the same code runs in about 0.02524 seconds.
But to demonstrate that it’s potentially much faster than PHP, imagine a benchmark like:
function add(int $a, int $b): int { return $a + $b; }
function add100(int $a, int $b): int {
$a = add($a, $b);
$a = add($a, $b);
$a = add($a, $b);
// ... snip 100 of these in total
$a = add($a, $b);
return $a;
}
In native PHP, that would take approximately 2.5 seconds to run 1 million times. Not exactly slow, but not insanely fast either. Using PHP-Compiler however, we see:
| Backend | Compile Time | RunTime (1,000,000 runs) |
|---|---|---|
| libjit | 0.000905990600585 | 0.31614589691162 |
| libgccjit | 0.036949872970581 | 0.34037208557129 |
| llvm | 0.000712156295776 | 0.26515483856201 |
So with that contrived example we can see a 10x performance boost over native PHP 7.4.
You can see this example, as well as the compiled code via the examples folder of php-compiler-toolkit
PHP-LLVM
The PHP-LLVM project was then created after PHP-Compiler-Toolkit. Since the Toolkit experimentation showed that there’s really no real benefit to libgccjit vs LLVM, and there’s performance benefits to LLVM as well as feature benefits, I decided to switch PHP-Compiler straight to LLVM.
So rather than using the LLVM C-API directly, I built a thin layer on top of it. This does two things: first, it presents a more “Object Oriented” API (to get the type of a value call $value->typeOf() rather than LLVMGetType($value)). Second, it allows me to abstract against different versions of LLVM. That way, ideally, support could be added for different versions of LLVM, and have capability checking to determine what’s supported.
PHP-ELF-SymbolResolver
Finally, due to a few bugs in LLVM, I needed a way to see what symbols were actually compiled into LLVM. So I needed to inspect the shared object file (.so) that contained the compiled LLVM library. To do that, I built PHP-ELF-SymbolResolver which parses ELF format files and extracts what symbols are declared.
For some reason I doubt there will be much need for this project outside of FFIMe, but maybe someone will need to decode a native OS library in PHP again. If so, here’s your lib!
The case for macros
While porting PHP-Compiler to use PHP-LLVM, it became apparent that code generation using a “builder” API just gets verbose quickly. It becomes write-only code. For example, take the relatively “simple” builtin function __string__alloc which allocates a new internal string structure. Using a builder API, it would look something like:
$fn = $this->context->context->addFunction(
'__string__alloc',
$this->context->context->functionType(
$this->context->getTypeFromString('__string__*'),
false,
$this->context->getTypeFromString('int64') // size
)
);
$this->context->functions['__string__alloc'] = $fn;
$block = $fn->appendBasicBlock('main');
$this->context->builder->positionAtEnd($block);
$size = $fn->getParam(0);
$allocSize = $this->context->builder->addNoSignedWrap($size, $size->typeOf()->constInt(1, false));
$type = $this->context->getTypeFromString('__string__');
$struct = $this->context->memory->mallocWithExtra($type, $size);
$offset = $this->context->structFieldMap[$struct->typeOf()->getElementType()->getName()]['length'];
$this->context->builder->store(
$size,
$this->context->builder->structGep($struct, $offset)
);
$offset = $this->context->structFieldMap[$struct->typeOf()->getElementType()->getName()]['value'];
$char = $this->context->builder->structGep($struct, $offset);
$this->context->intrinsic->memset(
$char,
$this->context->context->int8Type()->constInt(0, false),
$allocSize,
false
);
$ref = $this->context->builder->pointerCast(
$struct,
$this->context->getTypeFromString('__ref__virtual*')
);
$typeinfo = $this->context->getTypeFromString('int32')->constInt(Refcount::TYPE_INFO_TYPE_STRING|Refcount::TYPE_INFO_REFCOUNTED, false);
$this->context->builder->call(
$this->context->lookupFunction('__ref__init') ,
$typeinfo,
$ref
);
$this->context->builder->returnValue($struct);
$this->context->builder->clearInsertionPosition();
That’s a wall of garbage. Good luck understanding it (though it somewhat is readable, it’s really hard to work with).
So instead, I built a macro system using PreProcess.io and Yay. So now, the same code looks like:
declare {
inline function __string__alloc(int64): __string__*;
}
compile {
function __string__alloc($size) {
$allocSize = $size + 1;
$struct = malloc __string__ $size;
$struct->length = $size;
$char = &$struct->value;
memset $char 0 $allocSize;
$ref = (__ref__virtual*) $struct;
$typeinfo = (int32) Refcount::TYPE_INFO_TYPE_STRING | Refcount::TYPE_INFO_REFCOUNTED;
__ref__init($typeinfo, $ref);
return $struct;
}
}
Way more readable. It’s a mix of C and PHP syntax, and highly tailored to the needs of PHP-Compiler.
The macro language is semi-documented here.
And if you’re curious about the implementation, check out src/macros.yay.
If you’re worried about performance, you should be. These macros take a while to process (about 1 second per file). However, there are two methods to combat this.
First, it will only pre-process at all if you’ve installed PHP-Compiler with dev dependencies (using composer). Otherwise, it will just load the compiled PHP files.
Second, it will only pre-process “on the fly” if you’ve changed a .pre file, even with dev dependencies.
So in the end, the overhead is light for dev mode, and non-existant for production mode.
How do I run any of this?
First, install PHP 7.4 with the FFI extension enabled. There are no releases yet as far as I’m aware (and it’ll be quite some time until there is).
Running FFIMe:
For FFIMe, declare it as a composer dev-dependency ("ircmaxell/ffime": "dev-master"), and run the code generator via a rebuild.php style file. For example, the rebuild.php that PHP-Compiler-Toolkit uses contains something like this:
<?php
require __DIR__ . '/../vendor/autoload.php';
$ffi = new FFIMe\FFIMe('/opt/lib/libjit.so.0');
$ffi->include('/opt/include/jit/jit.h');
$ffi->include('/opt/include/jit/jit-dump.h');
$ffi->codegen('libjit\\libjit', __DIR__ . '/libjit.php');
// Or with a fluid interface:
(new FFIMe\FFIMe('/usr/lib/x86_64-linux-gnu/libgccjit.so.0'))
->include('libgccjit.h');
->codegen('libgccjit\\libgccjit', __DIR__ . '/libgccjit.php');
Then commit the generated files. I suggest including the generated files via composer via the files keyword instead of autoloading, because it’ll generate a TON of classes into that single file.
Replace the "...so.0" string with the path to the shared library that you want to load, and the .h file with the header(s) you want to parse (you can call ->include() multiple times).
I’d suggest playing with it, and opening Github issues for anything that you don’t understand or like. I won’t release it as stable until more people than me use it (and there are some tests/CI set up).
Running PHP-Compiler Natively
PHP-Compiler is in a really fluid state right now. So expect things to break. With that said:
First, install the dependencies (you can use LLVM 4.0, 7, 8, or 9):
me@local:~$ sudo apt-get install llvm-4.0-dev clang-4.0
me@local:~$ composer install
Now you’re set, just run it:
You can specify on the CLI via -r argument:
me@local:~$ php bin/jit.php -r 'echo "Hello World\n";'
Hello World
And you can specify a file:
me@local:~$ php bin/vm.php test.php
When compiling using bin/compile.php, you can also specify an “output file” with -o (this defaults to the input file, with .php removed). This will generate an executable binary on your system, ready to execute
me@local:~$ php bin/compile.php -o other test.php
me@local:~$ ./other
Hello World
Or, using the default:
me@local:~$ php bin/compile.php test.php
me@local:~$ ./test
Hello World
As far as what’s supported, that’s going to be changing pretty rapidly. Code that works today may not work next week. And the subset of supported PHP is really limited today…
Running PHP-Compiler With Docker
For convinence, two docker images are published for PHP-Compiler. Both are currently on an older version of Ubuntu (16.04) due to some issues with PHP-C-Parser that I haven’t gotten around to yet. But you can download and play with them:
ircmaxell/php-compiler:16.04 - A fully functioning compiler, all installed and configured with everything you’d need to run it.
ircmaxell/php-compiler:16.04-dev - The development dependencies only. This is designed to work with your own checkout of PHP-Compiler so that you can develop it in a consistent environment.
To run some code:
me@local:~$ docker run ircmaxell/php-compiler:16.04 -r 'echo "Hello World\n";'
Hello World
This will by default run with bin/jit.php. If you want to run with a different entrypoint, you can change the entrypoint:
me@local:~$ docker run --entrypoint php ircmaxell/php-compiler:16.04 bin/print.php -r 'echo "Hello World\n";'
Control Flow Graph:
Block#1
Terminal_Echo
expr: LITERAL<inferred:string>('Hello World
')
Terminal_Return
OpCodes:
block_0:
TYPE_ECHO(LITERAL('Hello World
'), null, null)
TYPE_RETURN_VOID(null, null, null)
Oh, and if you want to “ship” compiled code, then you can do that by extending the dockerfile. For example:
FROM ircmaxell/php-compiler:16.04
WORKDIR app
COPY index.php /app/index.php
RUN php /compiler/bin/compile.php -o /app/index /app/index.php
ENTRYPOINT '/app/index'
CMD ''
When you run docker build, it will compile the code in index.php and generate a native machine code binary at /app/index. That binary will then be executed when you run docker run ... (note: this isn’t designed for production use as the container will ship with a ton, but is more demonstrative of how this process could work).
What’s Next
Now that PHP-Compiler supports LLVM, work can continue building out more support for the language. There’s still a bunch to do (like Arrays, Objects, untyped variables, error handling, standard library, etc), so :D. There’s a ton that needs to be done in PHP-CFG and PHP-Types as well, including support for exceptions and references as well as fixing a couple of bug cases.
Oh, and tests are needed. Like a lot of them. And testers. Try it out, break it (it’s easy, I promise), and then submit an issue.
Can has tests pls?